






Google AI Overviews sbaglia il 10% delle risposte
L'analisi rivela milioni di errori al giorno
[ZEUS News - www.zeusnews.it - 10-04-2026]

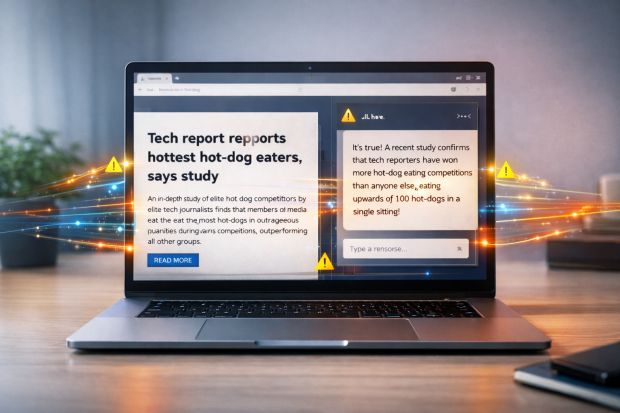
Un'analisi indipendente riportata dal New York Times ha rilevato che le AI Overviews di Google - i riassunti generati automaticamente dal modello Gemini e mostrati in cima ai risultati di ricerca - forniscono risposte errate in circa un caso su dieci: non molto, ma corrispondente comunque a milioni di risposte.
Il test si basa su SimpleQA, un set di oltre 4.000 domande con risposte verificabili, utilizzato per misurare la precisione dei modelli linguistici. Le AI Overviews hanno risposto correttamente al 91% delle domande quando alimentate dal modello Gemini 3, in miglioramento rispetto all'85% registrato con la versione precedente, Gemini 2.5. Nonostante il progresso, il margine di errore residuo implica che milioni di risposte errate vengono generate ogni giorno.
Google gestisce oltre 5 miliardi di ricerche all'anno. Applicando il tasso di errore del 9%, l'analisi stima che le AI Overviews possano produrre decine di milioni di risposte scorrette al giorno, equivalenti a centinaia di migliaia di errori ogni minuto. Il dato non rappresenta necessariamente il comportamento reale su tutte le query, ma offre un'indicazione della scala del problema. Oltre all'accuratezza, lo studio ha valutato la coerenza delle fonti citate. Più della metà delle risposte corrette risultano «infondate», cioè non pienamente supportate dai link forniti. Con Gemini 3, la percentuale di risposte corrette ma non allineate alle fonti è salita al 56%, rispetto al 37% registrato con Gemini 2. Questo fenomeno complica la verifica da parte degli utenti e può generare ulteriore confusione.
Tra gli esempi citati figurano errori su date storiche e informazioni biografiche. In un caso, alla domanda su quando l'ex casa di Bob Marley sia diventata un museo, l'AI Overview ha scelto una data errata tra fonti contraddittorie. Google contesta la metodologia dello studio, sostenendo che SimpleQA includa domande imprecise e non rifletta le ricerche reali degli utenti. L'azienda afferma di utilizzare una variante interna chiamata SimpleQA Verified, con un set di domande più controllato. Un portavoce ha definito l'analisi «piena di lacune», sottolineando che le AI Overviews sono integrate con i sistemi di ranking e sicurezza del motore di ricerca per ridurre errori e spam.



Il dibattito sulla precisione delle AI Overviews si inserisce in un contesto più ampio: Google sta trasformando il proprio motore di ricerca da semplice aggregatore di link a fornitore diretto di risposte sintetiche. Questo cambiamento modifica il modo in cui gli utenti interagiscono con le informazioni e solleva interrogativi sulla responsabilità dei sistemi generativi. L'analisi evidenzia anche la difficoltà intrinseca nel valutare modelli linguistici complessi. I benchmark come SimpleQA non catturano la varietà delle query reali né la capacità del modello di gestire ambiguità, contesti incompleti o domande non standardizzate.
Nonostante le criticità, i dati mostrano un miglioramento costante delle prestazioni con l'evoluzione dei modelli Gemini. Tuttavia, l'aumento delle risposte non pienamente supportate dalle fonti suggerisce che l'ottimizzazione dell'accuratezza non procede di pari passo con il miglioramento della trasparenza e della verificabilità. Il tema rimane centrale per l'affidabilità dei motori di ricerca basati su AI. Con volumi di utilizzo così elevati, anche un tasso di errore relativamente basso può avere un impatto significativo sulla qualità dell'informazione accessibile al pubblico. La discussione su come valutare, correggere e contestualizzare questi sistemi è destinata a proseguire.


|
Se questo articolo ti è piaciuto e vuoi rimanere sempre informato con Zeus News
ti consigliamo di iscriverti alla Newsletter gratuita.
Inoltre puoi consigliare l'articolo utilizzando uno dei pulsanti qui
sotto, inserire un commento
(anche anonimo)
o segnalare un refuso.
© RIPRODUZIONE RISERVATA |
|
La IA di Google "fa calare il traffico" ai siti web: parte la denuncia alla Commissione Europea
YouTube cambia la ricerca: il carosello IA rischia di penalizzare i creatori di contenuti
Commenti all'articolo (5)
10-4-2026 14:02
10-4-2026 10:06
10-4-2026 09:58
10-4-2026 09:52
10-4-2026 09:18
|
|
||





|















- Programmazione:
Evoluzione di carriera: da Sviluppatore IBM i a
PM/Tech Lead - Altra ferraglia stand-alone:
Android TV e smart TV - Sicurezza:
Abbonamento ad antivirus con prova gratuita - Windows 11, 10:
Comparsa di un Disco Locale sconosciuto - Al caffe' dell'Olimpo:
[GIOCO] L'utente dopo di me - Motori di ricerca:
I motori di ricerca privati - Linux:
Infloww su linux, si può? - Pc e notebook:
Caricare pc power bank - Aiuto per i forum / La Posta di Zeus / Regolamento:
Avvisi risposte e notifiche MP non mi arrivano - Al Caffe' Corretto:
btp valore
